Get started with asynchronous programming in Python

Principal Software Engineer at FWD.hr. FOSS enthusiast. Learning every day :)
Heard of async but you never really understood what it is or why you should use it? Hopefully, this article will help you understand the idea behind asynchronous code and when you really should use it instead of synchronous code.
NOTE: Since the full code snippet is not really that long, no final code will be provided on GitLab this time.
Prerequisites
As usual — some prerequisites before you get started:
Usage of venv is strongly recommended to keep your python packages separated from your host machine.
1. Asynchronous programming
So far you've been using synchronous code to make your scripts/apps in Python and you obviously haven't had the need to look for asynchronous implementations (or otherwise you wouldn't be here ^^). In some cases it is perfectly fine to use synchronous code, however, in some cases, it is completely wrong to do so.
The main difference between synchronous and asynchronous programming is in the way the code executes. A synchronous program is executed one step at a time and part of your code will run until it finishes and only then another part of your code can execute. An asynchronous program still runs one step at a time but with a difference that it may not wait for the running part of code to finish (e.g. return result) before moving on to the next part of your code. I will try to explain this with a picture below.
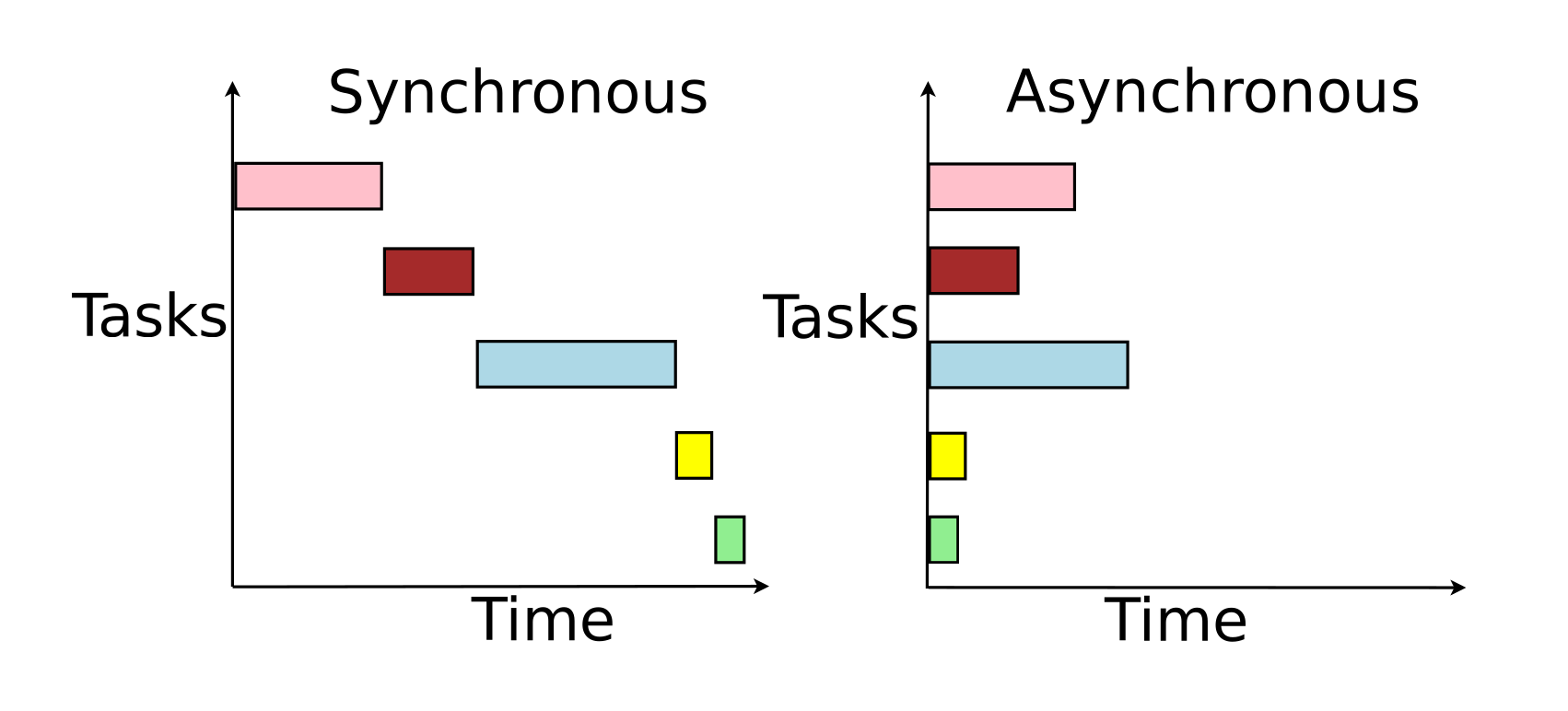 Synchronous vs asynchronous task execution
Synchronous vs asynchronous task execution
First of all - pardon my very basic diagram drawing skills...
As you can see, in both cases we have 5 tasks that we want to execute. On the left side of the diagram, you can see how synchronous task execution looks like. Each task executes and only when the task execution is finished another one can start. On the right side, you see the asynchronous task execution where all of the tasks are executed at the virtually same time, which means that after a task is executed, our code moves on to another one even if the task that was executed did not finish running. We can easily conclude that the running time of asynchronous task execution is much faster which can be seen by comparing the Time parameter on the both left and right side of the diagram.
1.1 When to use asynchronous code
While there is no definitive answer on when you should use async in Python, there are, however, some guidelines that will help you determine whether or not you should use async.
- Your code/task takes a long amount of time to complete
- I/O operations are blocking the rest of your code
- You ran several tasks one after another even though they are not dependant on each other
If your code hits any of the above targets, you should consider converting it into async code to speed things up. One practical example that I will show you will be based on the above guidelines. I want to send requests to several websites and check if I got a successful response from them. Let's jump to some good old Python coding :)
2. Python app
For benchmarking purposes, we will create both, synchronous and asynchronous, versions of the same website pinger app. Create a new Python project and along with it create a new venv that will hold our Python packages. Install the required Python packages:
pip install aiohttp
pip install fake_user_agent
pip install requests
The idea is to ping all of the Big Five websites. Create our main app.py file:
import time
import requests
GAFAM = [
"https://google.com",
"https://amazon.com",
"https://facebook.com",
"https://www.apple.com",
"https://www.microsoft.com",
]
def sync_run() -> None:
def _get_resp(url: str):
resp = requests.get(url)
if not resp.status_code == 200:
print(f"Error: {url} - {resp.status_code}")
for web in GAFAM:
_get_resp(web)
if __name__ == "__main__":
s_start = time.time()
sync_run()
s_end = time.time()
s_total = s_end - s_start
print("sync_run: %.4f" % s_total)
As you can see, only the synchronous version of the app is in the above example. So the idea, as I said earlier, is to ping a list of websites and to check if we can get a successful (200) response from each of them. In order to do so, we will make use of requests python package. We just want to make a simple GET request and check for the response. Inside the sync_run() method we are doing just that along with printing out everything that failed with a non-successful response. If you run the code above, you will indeed get an error - Error: https://amazon.com - 503. The reason why that happened is that some websites don't really like to get scrapped (targeted by bots) and they filter out such requests. The way most of them do that is by checking the request headers for User-Agent header. That is the exact reason why we installed the fake_user_agent python package. We want our bot to act like a human and therefore we will set its User-Agent header to one of the legitimate ones that you would see coming from the user.
Let's add another constant, above the GAFAM one, called USER_AGENT along with the needed import like this:
from fake_user_agent.main import user_agent
USER_AGENT = user_agent("chrome")
Now we need to make use of the USER_AGENT constant by injecting it into the headers parameter inside of our requests call (1st line of inside the inner _get_resp() method) like this:
resp = requests.get(url, headers={"User-agent": USER_AGENT})
Your code should now be error-free upon execution. Now that the synchronous part is done, we will move on to the async counterpart. We will make use of the async alternative for the requests package called aiohttp. Also, I will show you how to run tasks in parallel by making use of the asyncio python package.
Each asynchronous method starts with the async def keywords (unlike the synchronous def keyword). These methods are called coroutines. Every coroutine needs to be await-ed in order to get the response from the method. If you do not await your coroutine, it will never return the result since it will never execute.
Since we have a specific case where we want to execute multiple requests, we should create a task list that we will then execute all at once. Let's build our async version and analyze the code:
import asyncio
import time
import aiohttp
from fake_user_agent.main import user_agent
USER_AGENT = user_agent("chrome")
GAFAM = [
"https://google.com",
"https://amazon.com",
"https://facebook.com",
"https://www.apple.com",
"https://www.microsoft.com",
]
async def async_run() -> None:
async def _get_resp(url: str):
async with aiohttp.ClientSession() as session:
async with session.get(url, headers={"User-agent": USER_AGENT}) as resp:
if not resp.status == 200:
print(f"Error: {url} - {resp.status}")
tasks = []
for web in GAFAM:
tasks.append(_get_resp(web))
await asyncio.gather(*tasks)
if __name__ == "__main__":
a_start = time.time()
asyncio.run(async_run())
a_end = time.time()
a_total = a_end - a_start
print("async_run: %.4f" % a_total)
Obviously, the code is very similar to the sync version from earlier on. The key difference is that this time we execute all of the tasks (pings to the websites) together. We create a task list - tasks - that hold the calls to the inner coroutine _get_resp() with a different url parameter each time. I already mentioned that coroutines need to be await-ed in order to get the tasks to actually execute. We will achieve this by using asyncio.gather() which will run all of the tasks concurrently. Since the gather() method takes positional arguments instead of a single iterable (tasks) parameter, we need to unpack our list when using it. That way all of our tasks will be passed into gather() as separate arguments ready to be executed. The key part here is to await the asyncio.gather() in order to actually execute all of the tasks from the task list. Feel free to run the code. If you did everything ok, no errors should appear.
Benchmark/Conclusion
The final part is the merge of the two versions and checking the results. Let's do so:
import asyncio
import time
import aiohttp
import requests
from fake_user_agent.main import user_agent
USER_AGENT = user_agent("chrome")
GAFAM = [
"https://google.com",
"https://amazon.com",
"https://facebook.com",
"https://www.apple.com",
"https://www.microsoft.com",
]
def sync_run() -> None:
def _get_resp(url: str):
resp = requests.get(url, headers={"User-agent": USER_AGENT})
if not resp.status_code == 200:
print(f"Error: {url} - {resp.status_code}")
for web in GAFAM:
_get_resp(web)
async def async_run() -> None:
async def _get_resp(url: str):
async with aiohttp.ClientSession() as session:
async with session.get(url, headers={"User-agent": USER_AGENT}) as resp:
if not resp.status == 200:
print(f"Error: {url} - {resp.status}")
tasks = []
for web in GAFAM:
tasks.append(_get_resp(web))
await asyncio.gather(*tasks)
if __name__ == "__main__":
s_start = time.time()
sync_run()
s_end = time.time()
s_total = s_end - s_start
print("sync_run: %.4f" % s_total)
a_start = time.time()
asyncio.run(async_run())
a_end = time.time()
a_total = a_end - a_start
print("async_run: %.4f" % a_total)
print("async_run - sync_run: %.4f" % (s_total - a_total))
Once you run the full code you should see a huge difference between the two versions. In my case the output was:
sync_run: 2.8083
async_run: 0.8769
async_run - sync_run: 1.9315
Now, these numbers may not appear like that much of a big deal, but in reality, they actually are. We only tested five websites. Imagine what would happen if you try to check 100 000 websites. Even on this small set - in my case - we sped up our code by roughly 68.68%. Since speed is money in web development (smaller server/infrastructure cost and lower resource usage), you just saved yourself a nice amount of money just by making use of asynchronous programming :)
That would be all from me for this one — as always, thanks for reading!




